
 AWS Data into Splunk | By Swetha Muderasi | Splunk Consultant
AWS Data into Splunk | By Swetha Muderasi | Splunk Consultant
AWS Data into Splunk Seamlessly
Integration between Splunk Enterprise or Splunk Cloud, and Amazon Kinesis Data Firehose is designed to make AWS data ingestion setup seamless, while offering a secure and fault-tolerant delivery mechanism. Splunk makes it convenient to monitor and analyse machine data from any source and use it to deliver operational intelligence, optimise infrastructure operations, maximise security, and increase business performance. Kinesis Data Firehose allows you to use a fully managed, reliable, and scalable data streaming solution to Splunk. In this post, we discuss a step by step procedure of Kinesis Data Firehose and Splunk integration so you can seamlessly ingest AWS data into Splunk.
This is a push-based approach that offers a low-latency scalable data pipeline made up of serverless resources like AWS Lambda sending directly to Splunk indexers by using Splunk HEC. This is different from the Pull-based approach using Splunk-add-on for AWS.
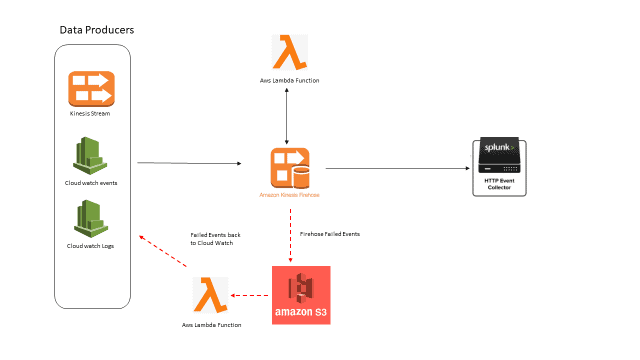
Figure 1 Splunk to Fire Hose Integration Architecture
Features and Benefits:
- Easy launch and configuration
- Load new data in near real time with no latency
- Elastic scaling to handle varying data throughput
- Integrated data transformations
- Support for multiple data destinations
- Pay-as-you-go pricing
- Process hundreds of gigabytes of data per second
- No overhead of maintenance for forwarders or latency issues
Key Concepts of AWS data into Splunk
Delivery stream
The underlying entity of Kinesis Data Firehose, you use Kinesis Data Firehose by creating a Kinesis Data Firehose delivery stream and then sending data to it.
Record
The individual data element of interest that your data producer sends to a Kinesis Data Firehose delivery stream. A record can be as large as 1,000 KB.
Data producer
Producers send records to Kinesis Data Firehose delivery streams. For example, a web server that sends log data to a delivery stream is a data producer.
Buffer size and buffer interval
Kinesis Data Firehose buffers incoming streaming data to a certain size or for a certain period of time before delivering it to destinations. Buffer size is in MBs and Buffer Interval is in seconds.
How Integration Works?
The below image represents the exact architecture of sending cloud watch logs to Splunk via firehose.
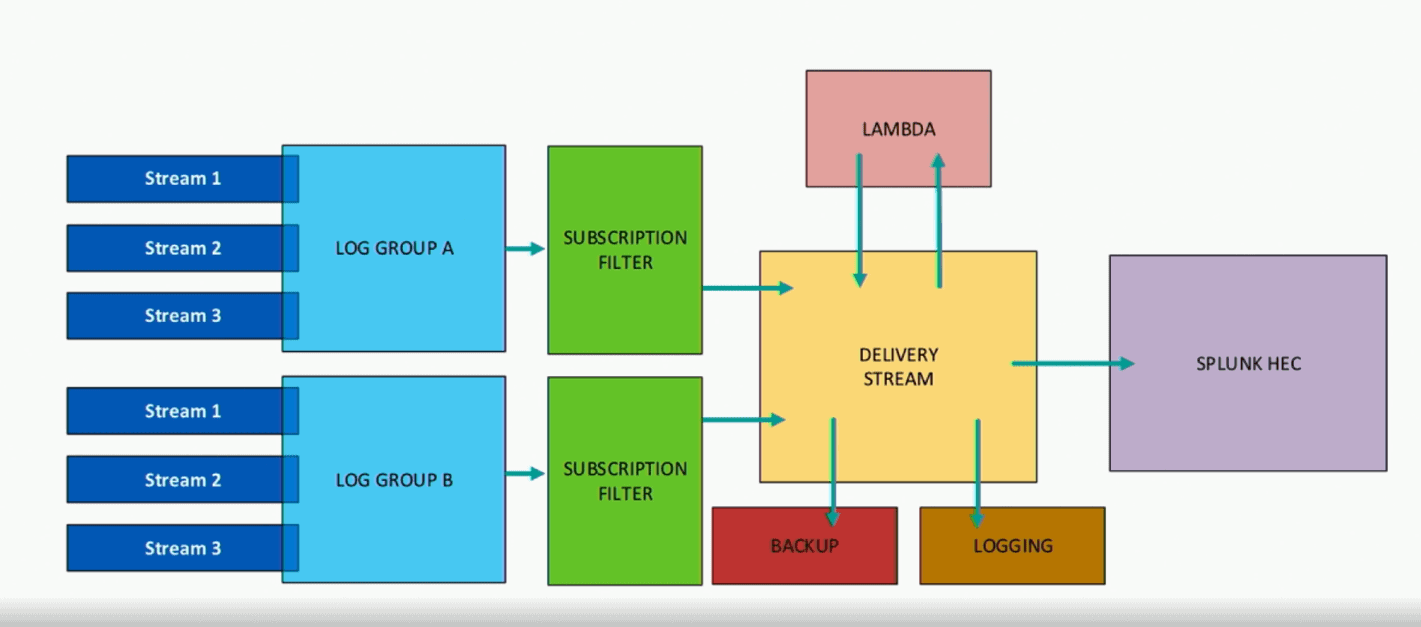
1. Pre-Requisites:
- Ensure the organisation’s firewall has a rule to allow connectivity from AWS to the Splunk Enterprise or Splunk Cloud over HTTPs to allow AWS data into Splunk.
- Confirm the number of data sources (Indexes, Sources, Source types).
- Confirm the number of Delivery Streams required (unique combination of Index and Source type).
2. Splunk end:
- Create HEC Tokens on Splunk SH or Splunk IDM (for cloud Instances) and select the respective index and source type.
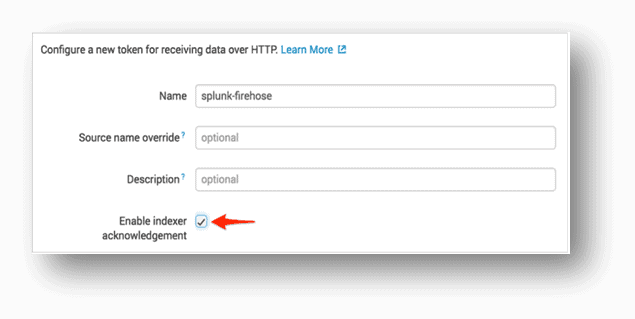
- Copy the token value and share the token and end point with the AWS team.- For managed Splunk Cloud, End point URL in this format: https://http-inputs-firehose-<your unique cloud hostname here>.splunkcloud.com:443)
– For Splunk Enterprise, End point URL is https://<IP Address>:8088 - Override the source to a relevant value since the default source value from the firehose will be http:<Token Name>.
- Enable Indexer acknowledgement.
3. AWS end:
- Create an S3 backsplash bucket for backup of failed events.
- Create a Firehose Delivery Stream.
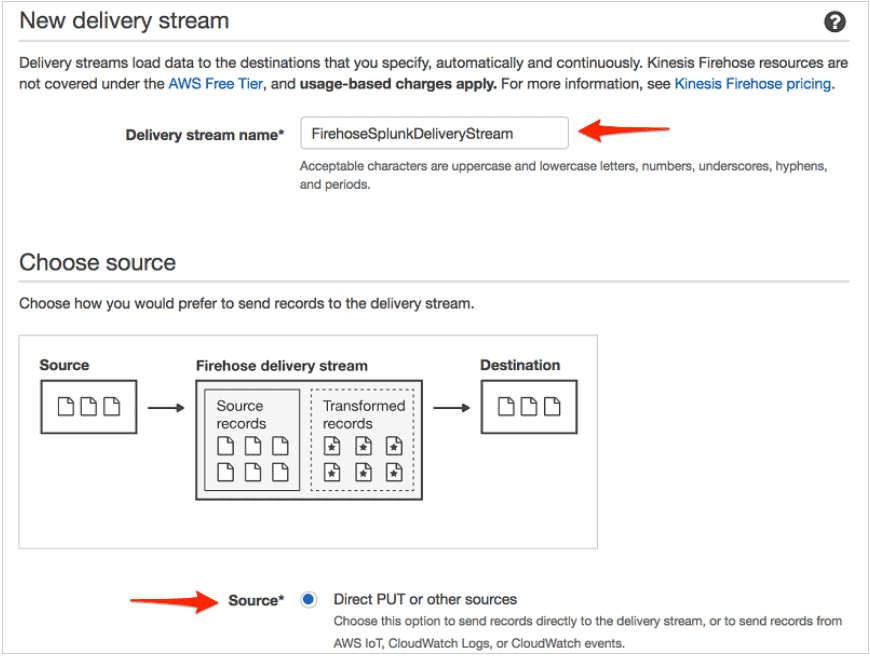
- Choose Enabled for Record transformation.
- Cloud Watch Logs are gzip level 6 compressed and hence we need a Lambda function to uncompress the events before firehose starts reading data. Create a Lambda Function and choose the kinesis blueprint suggested by AWS to uncompress the cloud watch events. (Kinesis Data Firehose Cloud Watch Logs Processor)
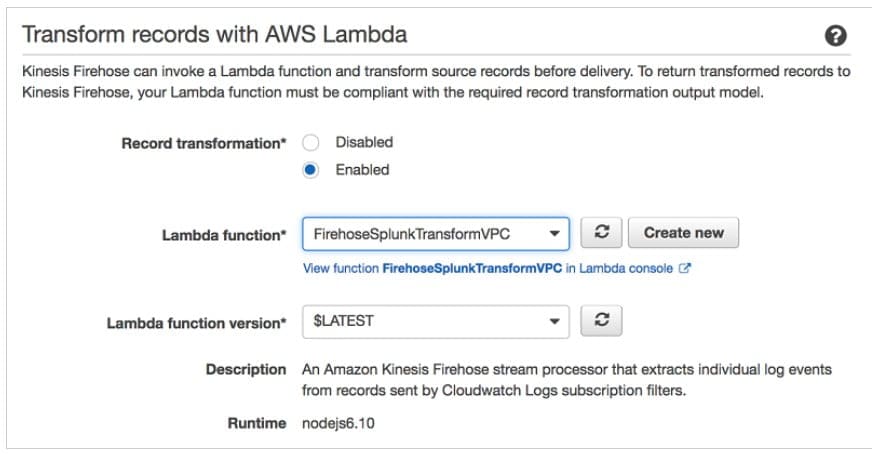
- Enter Splunk Destination Details, the HEC Token and Cluster End point.
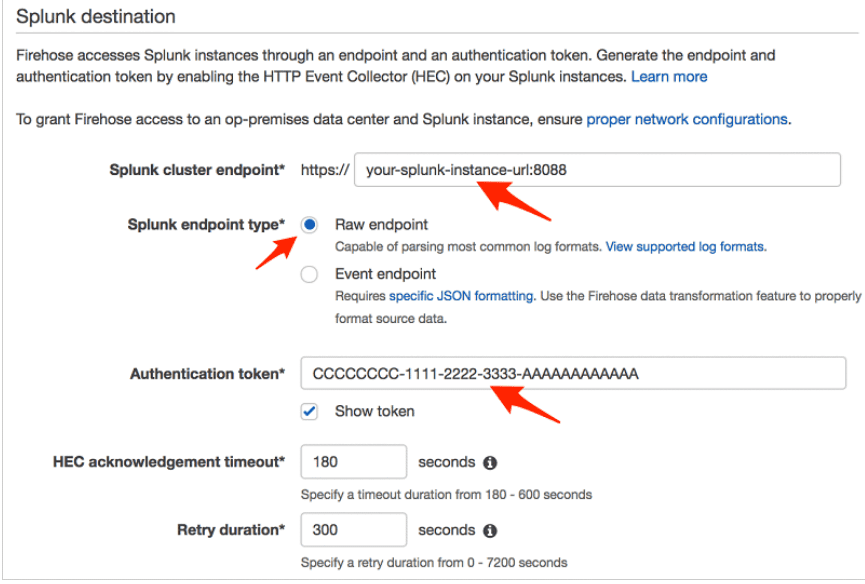
- Enter S3Backup Details. Note: Once the backup option is selected this cannot be changed in future, in case of any changes required delivery stream needs to be deleted and recreated.
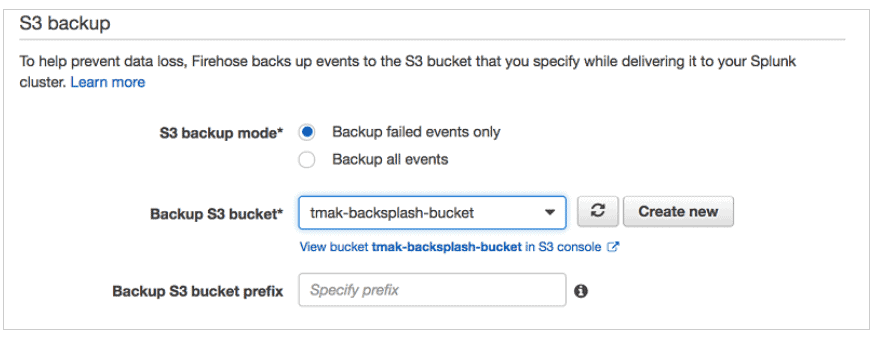
- To monitor your Firehose delivery stream, enable error logging. Doing this means that you can monitor record delivery errors.
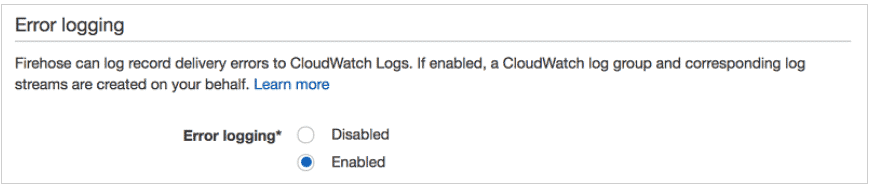
- The failed records backed up in the S3 bucket are in base-64 encoded format since the firehose by native writes records in base-64 encoded.
- There is a need of lambda function to decode the failed events before they are written to s3 bucket and blue print is available to decode the events.
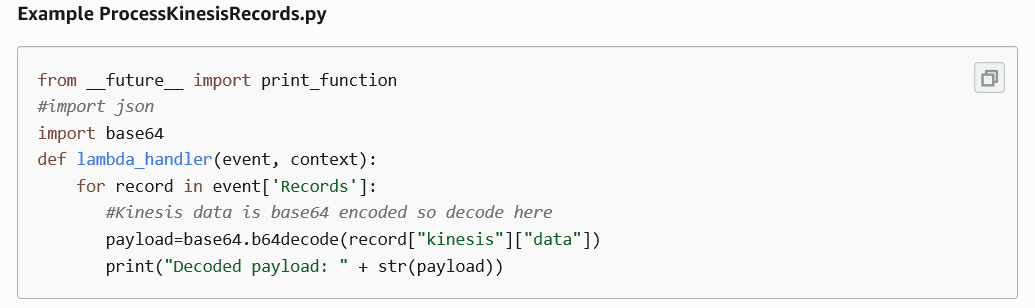
- Once the delivery stream is created, we have to now create a cloud watch log group and attach a subscription filter to push the data to firehose.
4. Creation of VPC Flow Log:
- Create a VPC Flow Log
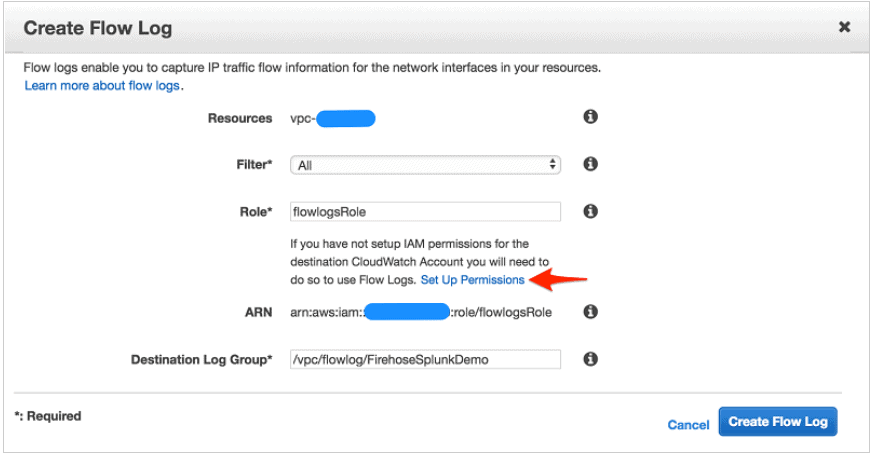
- Choose VPC, Your VPC, and choose the VPC you want to send flow logs from.
- Choose Flow Logs, and then choose Create Flow Log.
- Create New role that allows your VPC to publish logs to Cloud Watch.
- Choose Set up Permissions and Create new role.
- Once VPC flow log is active it looks like following.

- Publish Cloud Watch to Kinesis Data Firehose
- Set up Subscription Filter.

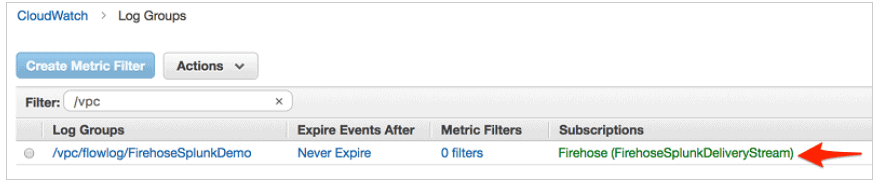
- Setting this up establishes a real-time data feed from the log group to your Firehose delivery stream.
- The real-time log data from the log group goes into your Firehose delivery stream.
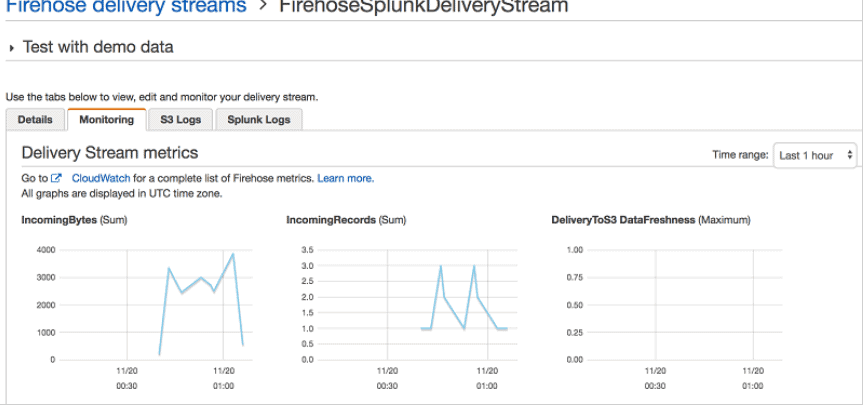
- This completes the delivery stream set up.
Fail Over Mechanism for AWS data into Splunk:
We propose the below failover mechanism to ensure failed events are brought back into Splunk and are reflected in the dashboards.
- The S3 bucket created above stores firehose failed events. The point of failure can be caused by Splunk being down or the HEC token getting corrupted or any such cause.
- The failed events in s3 bucket are expected to be flown back to Splunk through the delivery stream ensuring no data leakage.
- To achieve this, the data is stored in s3 bucket and a lambda is needed to check if the delivery is back up and running state at frequent intervals.
- Once the lambda detects the delivery stream is up and running, the data from s3 is sent to cloud watch so the firehose reads them and sends to Splunk via the delivery stream.
- The flow is depicted in red lines in Figure 1.
Possible Errors and Troubleshooting:
Once the delivery stream is up and running for AWS data into Splunk, Splunk should start receiving the events. Check the below areas where the possible errors could have occurred:
- The AWS delivery stream saves Splunk logs – check the Splunk logs for the errors.
- Check the end point is correct.
- Ensure the indexer acknowledgment is enabled in the HEC token input.
- Ensure the connectivity exists between the Splunk cloud and AWS instance.
Limitations Observed in AWS data into Splunk:
- No Metadata available at Splunk. The firehose does not send the host source values to Splunk. This makes the developers difficult to limit the searches.
- Every customisation needs a Lambda Function to be created. Metadata can be made available at Splunk with the help of Lambda.
- All the AWS data into Splunk that is to be sent via firehose should be written to cloud watch as we cannot read from AWS resources directly.
- Back up data from S3 is in a different format from the actual data, therefore dashboards /alerts cannot be reused.
Addendum: Firehose vs SQS:
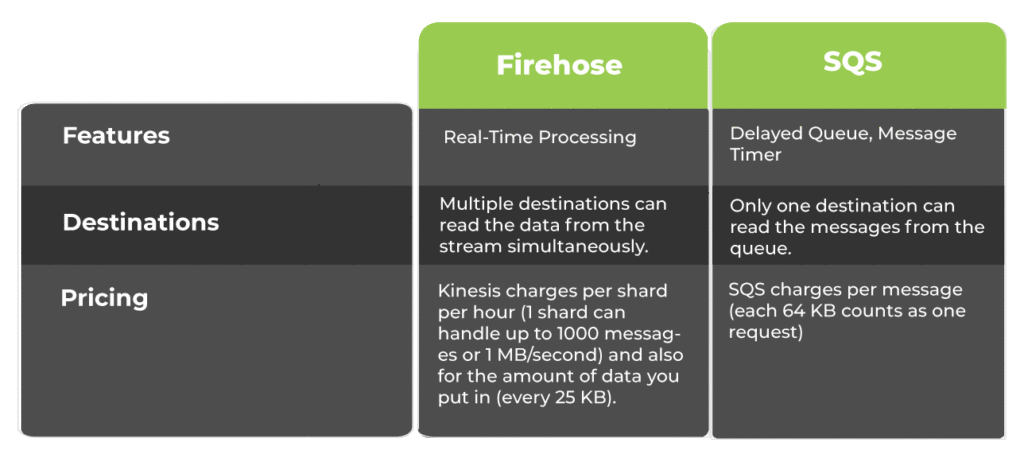
Using the methodology described above, it is possible to not only ingest AWS data into Splunk, but to create a robust integration and maximise uptime. By using Kinesis Firehose and the Splunk HTTP Event Collector, it is possible to minimise latency and create a solution that can be expanded almost without limit as your requirements grow.
Avocado has a dedicated Splunk team within our Engineering practice that holds the capabilities, experience, and certifications across a broad range of Splunk solutions. If you want to discuss AWS data into Splunk further or if there is a topic you would like the Avocado team to cover in another Tech Tip contact us at [email protected].
